
From EC2 to Kubernetes: Our Journey to a Scalable Infrastructure
How We Transformed Our Infrastructure and Developer Operations with Docker, Kubernetes, Pulumi, and Jenkins—Scaling Smarter, Not Harder


Transitioning from a traditional EC2 setup to a Kubernetes architecture was more than just a technical migration for us—it was a transformative journey filled with challenges, learnings, and growth. This is the story of how we navigated this complex path, the obstacles we faced, and how we emerged with a more scalable, efficient, and reliable infrastructure.
The Beginning: Outgrowing Our EC2 Setup

Back in the early days, our infrastructure was built entirely on Amazon EC2 instances. It was straightforward, familiar, and served our needs well. We could spin up instances, configure them as needed, and get our applications running without much fuss.
However, as Storylane started to see growth, so did the demands on our systems and processes. We started noticing cracks in our overall system:
Scaling Challenges: Scaling required manual intervention—spinning up new instances, configuring them, and integrating them into our environment.
Development Bottlenecks: Setting up multiple non-production environments for testing and development was cumbersome and time-consuming.
Inconsistent Environments: Differences between development, testing, and production environments led to unexpected issues during deployments.
We realized that our current infrastructure wouldn't sustain our growth trajectory. We needed a solution that could scale with us, improve efficiency, and support rapid development cycles.
Our Weapons of Choice: Containerization, IaC, and CI/CD

Embracing Docker
We began by Dockerizing all our services. This process involved:
Creating Docker Images: Packaging each application with its runtime, libraries, and configurations.
Standardizing Environments: Ensuring that every environment—development, testing, production—ran the same container images.
Docker solved many of our consistency issues, but we still needed a way to manage these containers at scale.
Enter Kubernetes
With the challenges that we faced, it was a no brainer for us - Kubernetes.
Why Kubernetes?. Because it offered:
Automated Deployment and Scaling: Easily deploy applications and scale them up or down based on demand.
Self-Healing Capabilities: Automatically restart failed pods and reschedule them when nodes die.
Declarative Configuration: Manage infrastructure through code, making it easier to replicate environments.
Pulumi for the win!
As our infrastructure grew, manual provisioning of infrastructure became cumbersome. We need a Infrastructure as a Code solution to keep up with our growing requirements. Terraform was not even considered since that was moved from an open source to a business source license last year.
Why Pulumi? Because it allowed us to:
Use a Familiar Language: The Go programming language was used. Although there is an initial investment where it takes a bit longer to setup compared to a untyped programming language like Python or JavaScript, but once done correctly, the velocity is much, much better. Go was my personal preference, even TypeScript is a good option.
Version Control: Keep track of the new additions / changes that are made to the infrastructure.
Velocity: You would think that provisioning infrastructure is faster and easier through the GUI, but its really not. Once you have a maintainable codebase that oversees your entire infrastructure, with just a single command, multiple components across different services can be easily created.
Pulumi enabled us to automate, standardize, and scale our infrastructure efficiently, reducing errors and improving consistency across environments.
Streamlining CI/CD with Jenkins
With all our microservices Dockerized and running on Kubernetes, we needed a robust CI/CD solution to handle continuous integration and deployment. Jenkins was the clear choice for us due to its flexibility and large ecosystem of plugins.
Why Jenkins? Because it offered:
Automated Builds and Tests: Each commit triggered automated builds and tests across all microservices, ensuring that only reliable code made it to production.
Seamless Integration with Kubernetes: Jenkins pipelines were configured to deploy applications directly to our Kubernetes clusters, simplifying the deployment process.
Scalable Pipelines: We used Jenkins agents to handle the parallel builds and deployments of multiple microservices, making the entire process fast and efficient.
Jenkins enabled us to maintain a smooth and reliable deployment process, ensuring that our services could be deployed frequently and without manual intervention.
Planning the Migration: A Two-Phase Approach
We decided to tackle the migration in two phases:
Development Environment Migration
Production Environment Migration
Phase 1: Migrating the Development Environment
Our first goal was to transition our development setup to Kubernetes. This was done so that we can tackle all the issues first in a non-production environment, figure out how it behaves in a Kubernetes environment, and most importantly, come up with the configuration that would serve our traffic requirements seamlessly.
Step 1: Dockerizing Services
We started by Dockerizing all our services, creating consistent images for each application. This included all our microservices, right from the frontend to the backend, as we could not afford migrating the services in phases. We wanted to migrate the entire product to Kubernetes.
Step 2: Creating Helm Charts
Next, we created the Helm charts for each service, which served as templates for deploying all our micro-services to Kubernetes.
Step 3: Testing with Minikube
To test our Kubernetes setup without incurring additional costs, we used Minikube to run a local Kubernetes cluster. This allowed us to:
Iterate Quickly: Test changes locally before deploying to a managed service like AWS EKS.
Identify Issues Early: Catch configuration errors or compatibility issues in a controlled environment.
After testing and refining, we successfully migrated our development environment to Kubernetes running on the x86 architecture. This is a key point, as the underlying architecture plays a major role later while migrating the production environment.
Step 4: Testing on EKS with the dev team
We then created two lower environments on EKS - dev and staging, separated by Kubernetes namespaces. Now, it was time for the development team to work with these two lower environments on Kubernetes.
I need to give a special shout out to the entire development team at Storylane for keeping up with all the issues that showed up during the initial days after the migration.
Once all the issues were resolved, everything was running smoothly on the dev environment, it was time for us to move forward with the Kubernetes environment and move away completely from the EC2 instance based setup.
Phase 2: Migrating the Production Environment
With confidence from our development migration, we turned to the production environment.
The Graviton Opportunity
We saw an opportunity to improve performance and reduce costs by using AWS Graviton instances based on the ARM architecture. This required:
Rebuilding Docker Images for ARM: Ensuring all our services and their dependencies were compatible with ARM.
Library Compatibility Checks: Identifying and replacing any libraries that didn't support ARM.
Extensive Testing: Verifying that all features worked as expected, especially those involving multiple services.
Ensuring Zero-Downtime Migration
As an enterprise SaaS business, there was never a discussion about incurring downtime. It was pretty clear from day 0 that we cant have any downtime, at all. This is the plan that we came up with to migrate with zero downtime:
Parallel Environments: We set up the new Kubernetes environment in a separate VPC for enhanced security and reliability.
Database Replication with AWS DMS: We used AWS Database Migration Service (DMS) to replicate data from our existing RDS instance to a new one, in the new VPC, in real-time. We went with the serverless offering of AWS as was more cost effective for our use case, I’ll explain why. The initial load was significant, and took 16 serverless compute units. CDC (Change Data Capture), which is the real-time data replication, this only required 4 compute units. The initial load took an entire day to complete, but once that was done, the serverless setup automatically scaled down to 4 compute units.
Gradual Cutover: Once everything was in place, we updated our DNS records to point to the new environment. We kept the old environment running temporarily to account for DNS caching and to ensure a seamless transition.
Overcoming Challenges Along the Way
Technical Hurdles
ARM Compatibility: Some libraries for some of our services didn't support ARM out of the box. We had to x86 node groups in our EKS cluster for those specific services.
Complex Configurations: Setting up Kubernetes configurations for all services was intricate and required meticulous attention to detail.
Data Synchronization
Database Migration: Setting up real-time replication with AWS DMS was complex as there are various things that are not supported out of the box with DMS like custom Postgres extension, certain types of Indexes, etc.
Ensuring Consistency: Validation of the Initial data load was also time consuming as this was the customer data on production, and we couldn’t afford any data loss or inconsistency.
Team Adaptation
Upskilling: The team needed to learn to work with new technologies—Docker, Kubernetes, Jenkins, and more.
Cultural Shift: Adopting a DevOps culture around Kubernetes meant changing how we collaborated, breaking down silos between development and operations.
Security and Compliance
Maintaining Compliance: We needed to ensure that our new infrastructure met GDPR and SOC 2 requirements from day one.
Implementing Security Layers: Ensuring that the critical resources were secure at the network layer, as well as, the lower levels. For this, we used the AWS Client VPN endpoints for network-level security and RBAC policies along with security groups for lower level access control.
Reaping the Benefits: Performance and Reliability Enhancements
Self-Healing Infrastructure
Kubernetes' self-healing capabilities meant that if a service crashed, Kubernetes would automatically restart it. This significantly reduced downtime and improved reliability.
Resource Optimization
By using different node groups for different services, we achieved:
Improved Performance: Services weren't competing for resources, leading to better performance.
Scalable Architecture: We could scale node groups independently based on service demand.
Cost Efficiency: Although this approach increased complexity, it allowed for better resource utilization.
Monitoring and Observability

We integrated several tools to monitor and observe our systems:
Prometheus and Grafana: For real-time metrics and dashboards.
Thanos: For scalable, long-term storage of Prometheus metrics.
Loki and Promtail: For centralized logging and log aggregation.
Slack Alerts: To stay informed about system performance and issues in real-time.
Strengthening Security: Beyond the Basics
Network and Cluster Security
AWS Client VPN: Provided secure access to our Kubernetes cluster and internal tools, ensuring only authorized personnel could connect.
Role-Based Access Control (RBAC): Used IAM roles and RBAC policies to control access within the cluster.
Secrets Management
We opted to use AWS Secrets Manager instead of Kubernetes secrets:
Enhanced Security: Secrets Manager offered better encryption and access control.
Simplified Management: Easier to manage and rotate secrets as needed.
Deployment Strategies and Best Practices
Blue-Green Deployment
For the frontend applications, we opted for this strategy because:
Zero-Downtime Updates: We could deploy new versions without affecting the current running version.
Testing in Production: Allowed us to test the new version in a live environment before fully switching over.
Rolling Deployments
For the backend services, we opted for this strategy as it allowed for:
Gradual Updates: Replaced instances of the application one at a time to ensure stability.
Database Migrations: Tested thoroughly in lower environments to prevent issues during production deployments.
Multiple Environments across two Clusters
Development Environments: Lightweight setups for individual developers to test changes.
UAT (Pre-Production) Environment: Mirrored a cost-effective production environment for final testing before any new release.
Production Environment: The live environment serving our users.
Fostering Team Collaboration and Communication

One of the key shifts during our migration was adopting a true DevOps culture. By breaking down the barriers between development and operations, we fostered a sense of shared responsibility across the entire team. Everyone was aligned, working towards the same goal—building a more reliable and scalable system.
We began by streamlining the CI/CD pipelines with Jenkins, where a commit on specific branches automatically deployed to their respective environments in Kubernetes. Once the code was deployed, a Slack bot sent a notification to the deployment channel, making it easier for the team to know when the pipeline was done.
Later, we enhanced the same Slack bot to allow deployments of any branch to the lower environments (non-production) with just a single Slack command.
Automation played a major role here—by automating builds, tests, and deployments, we eliminated many of the manual errors that used to slow us down.
Transparency was also crucial. With real-time Slack notifications for every deployment, everyone stayed in the loop. This level of visibility not only improved communication but also ensured that any potential issues were quickly identified and addressed.
Measuring Success: The Outcomes
Seamless User Experience
Our primary goal was to ensure that users were unaware of the migration. We achieved:
Zero Downtime: No service interruptions during the transition.
Consistent Performance: Users experienced improved performance without any negative impacts.
Performance Improvements
Faster Load Times: A 15% reduction in initial load times because of the move to the ARM architecture enhanced the user experience.
Scalability: Our infrastructure could now handle three times more traffic, with room to scale further.
Cost Savings
When you build a new infrastructure from the ground-up like we did, it’s easier to identify some of the inefficiencies and improve them.
ARM Instances: Leveraging AWS Graviton instances lowered our operational expenses.
General Upgrades: Components like the database (RDS) and the cache (ElastiCache) were upgraded to the latest versions and instance types, making them more cost-efficient.
Operational Efficiency
Pipeline Automation: Automated pipelines and streamlined processes sped up deployments.
Improved Reliability: Self-healing infrastructure and better monitoring reduced incidents.
Reflecting on the Journey
Looking back, the migration was a significant undertaking that required an effort of more than 6 months, collaboration, and innovation. It wasn't just a technical upgrade—it was a transformation of how we operate.
Lessons Learned
Thorough Planning is Crucial: Detailed migration plans helped us navigate complex challenges.
Invest in Your Team: Training and supporting the team ensured a smooth transition.
Embrace Automation and Infrastructure as Code: Tools like Pulumi and Jenkins streamlined our processes.
Prioritize Security and Compliance: Building security into every layer right from day zero prevented issues down the line.
Stay Adaptable: Being ready to adjust plans helped us overcome unforeseen obstacles.
The Final Architecture
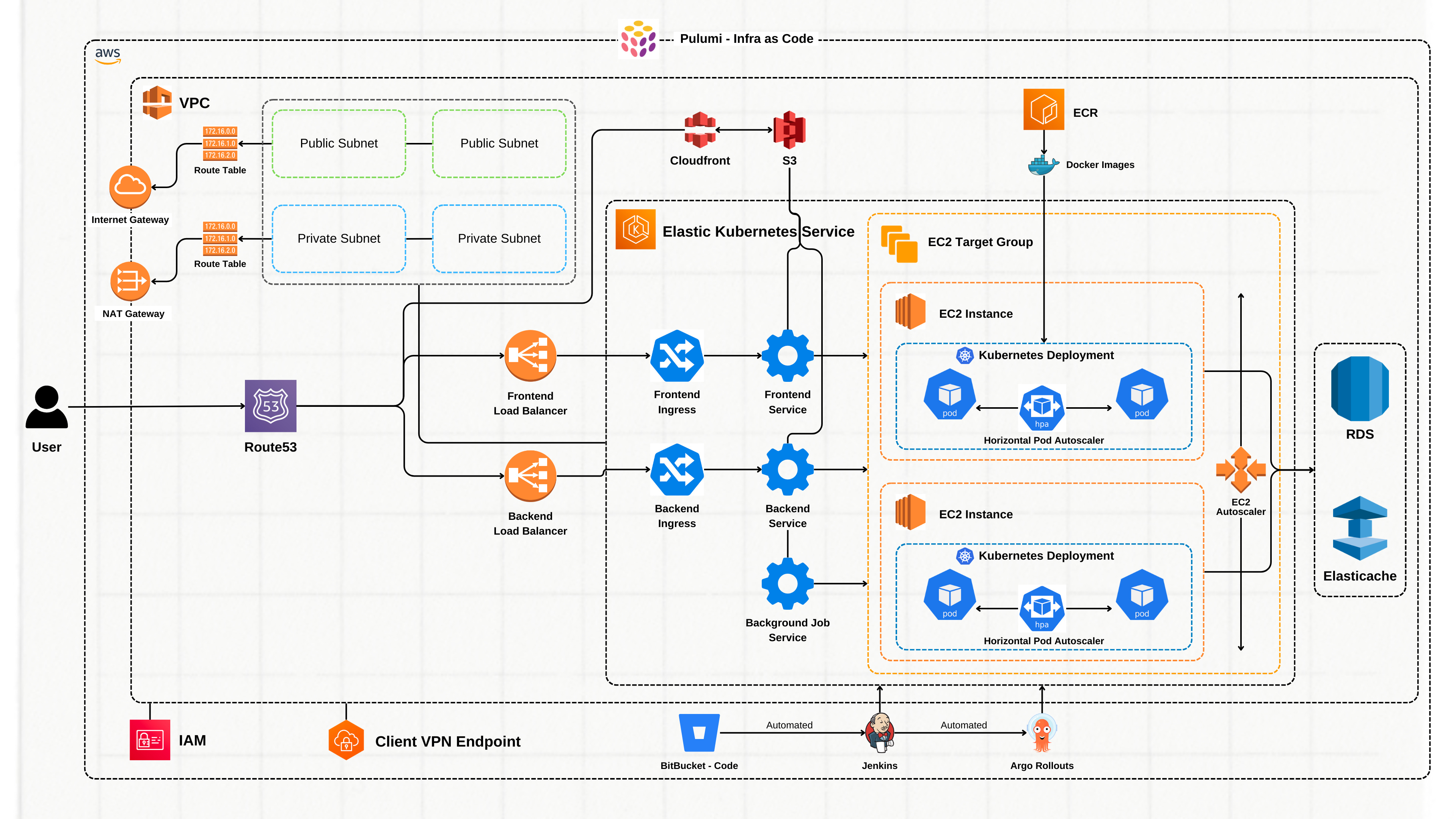
Yes! This is the final architecture we ended up with, and I definitely sleep better at night knowing we’re relying on proven, open-source tools that we can trust. Is this the end of the road? Not at all! As Storylane continues to grow and evolve, with new features being rolled out every few weeks, this architecture will evolve alongside it. But rest assured, we’ll continue to share our learnings as we move forward.
Conclusion: A New Chapter
Our journey from EC2 to Kubernetes was challenging but immensely rewarding. We've built a scalable, efficient, and robust infrastructure that not only meets our current needs but also sets us up for future growth.
To anyone considering a similar path, we hope our story provides insight and inspiration. Embrace the challenges, invest in your team, and keep the end goal in sight. The transformation is worth the effort.
Epilogue: Sharing Our Story
By sharing our experience, we aim to contribute to the collective knowledge of the tech community. Whether you're a fresh graduate stepping into the cloud domain or an experienced professional navigating infrastructure challenges, we hope our journey offers valuable lessons and encouragement.
Let's continue to learn from each other, innovate, and build the products of the future together.